

Contents
Overview
The pipeline mode of the SeqSphere+ client allows to perform the assembling (SKESA, SPAdes, Velvet, or BWA), importing, analyzing and typing of hundreds of your NGS sequence data automatically without further interaction. The workflow of a pipeline is defined by a pipeline script. This script can be created interactively by a step-by-step dialog without scripting skills. Pipeline scripts are always stored on the computer in the profile directory of the user where the SeqSphere+ Client is installed that was used to define a script. Pipelines can also be run in parallel on multiple computers to reduce the total processing time.
The pipeline mode is strongly recommended
- if WGS reads should be assembled, or
- if more than ~50 Samples should be imported at once, or
- if a fully automatized workflow should be established.
Starting the Pipeline Mode
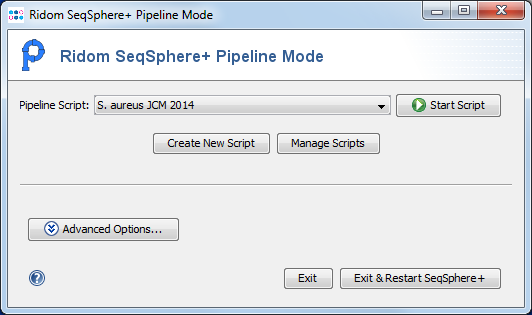
To avoid dependencies, the pipeline mode can only be started in the SeqSphere+ client if the user is not logged in.
Click on the link ![]() Start Pipeline Mode below the login panel or choose the topic in the File menu to start the pipeline mode.
Start Pipeline Mode below the login panel or choose the topic in the File menu to start the pipeline mode.
The standard window closes and the pipeline mode window is shown.
Use the ![]() Start Script button to start a pipeline for a defined pipeline script.
Use the 'Create New Script and Manage Scripts buttons to create and manage the pipeline scripts.
Start Script button to start a pipeline for a defined pipeline script.
Use the 'Create New Script and Manage Scripts buttons to create and manage the pipeline scripts.
The Start Schedule button allows to start multiple defined pipelines in succession.
![]() Hint: The SeqSphere+ client can also be directly started in the pipeline mode using command line parameters.
Hint: The SeqSphere+ client can also be directly started in the pipeline mode using command line parameters.
Monitoring Running Pipeline
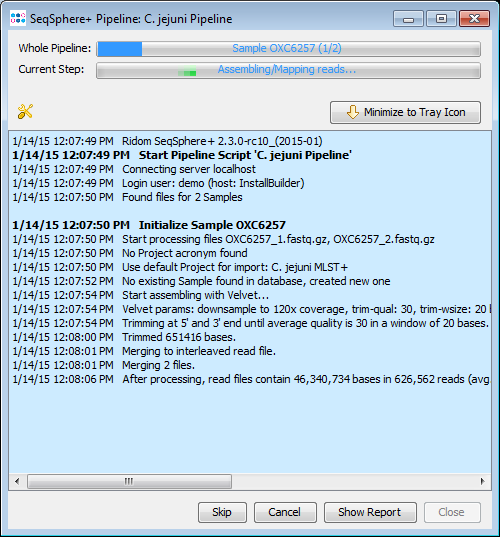
When the pipeline is started, the progress window is shown. The progress window can be minimized to a tray icon.
On the bottom of the window the following control buttons are available:
- Skip: Skip the currently processed Sample and continue with next.
- Cancel: Cancel the running pipeline immediately or after the current Sample. Depending on the current step of the pipeline the immediate cancellation will take a few seconds.
- Stop: Only available for pipelines running in continuous mode. Stop and finish the pipeline when it is currently waiting for new files.
- Show Report: Show the the current report for the pipeline.
- Close: Close the window. Only available if the pipeline is not running.
Viewing the Pipeline Results

The results of a pipeline run are summarized in the Pipeline Report. Use the button Show Report to open the report.
For more details and further analysis (e.g., comparison table) start the SeqSphere+ client and use the normal log in to see the results. The most current pipeline reports are shown in the Recent Pipeline Reports section of the home screen.
Use the menu function ![]() Tools | Browse Pipeline Reports to see all pipeline reports.
Tools | Browse Pipeline Reports to see all pipeline reports.
Running Pipelines in Parallel
Pipelines can be run on multiple computers in parallel to reduce the total processing time. All processing computers can read the input data from the same shared network folder. If a Sample is processed by one computer, it is automatically skipped by all other computers.
All processing computers must have a file system access to the input data (FASTA, ACE, BAM, or FASTQ). Therefore, a network drive must be defined (recommended on Windows) or mounted into the file system first (e.g., smbfs on Linux). The definition of the pipeline scripts can be simplified if the input data folder has the same file system path on all computers (i.e., same network drive letter on Windows, or same mounting point on Linux). All pipelines can run simultaneously with the same user account.
The following FAQ pages describe how to distribute a pipeline script and run it on multiple client computers (including those without a graphical user interface) in parallel. Furthermore it is described how to control multiple running pipelines from any client computer with a graphical user interface.