

Overview
The Sequencing Run Details in SeqSphere+ contain the details of a sequencing run PacBio platform. They are automatically read and imported by a SeqSphere+ assembling pipeline, if the required PacBio run info files (see below) are found together with the FASTA/BAM files. The Sequencing Run Details are stored in the database and can be used for further quality control on run level.
The Sample procedure details field Sequencing Run ID is used to hold the run ID as a reference to the stored run details. The field Sequencing Run QC is used for QC warnings. If not set by the manually defined procedure details, the Sequencing Length and Sequencing Platform are also filled from the run details.
Required PacBio Run Files
The following PacBio run directories and files are required to import Sequencing Run Details:
- Sample sheet CSV file (e.g., 28.09.2020_B8101.csv) or Sample sheet XML file (e.g., B8789-220817_rundata.xml)
- JSON file with id loading_xml_report (e.g., Run_loading.report.json)
- JSON file with id raw_data_report (e.g., Run_raw_data.report.json)
If the pipeline is defined to import FASTA/BAM files from a Directory, all required files mentioned above. These figures are P0, P1, P2, percentage of productivity.
When importing samples in a pipeline, SeqSphere+ compares the imported sample names with names indicated in the sample sheet. If sample sheet CSV and XML both are available then CSV file is considered to compare imported sample names. If any of the processed samples do not appear in the sample sheet, a warning message is written in the pipeline log. If a sample that is listed in the sample sheet is missed, no warning message is stated. However, both, extra and missing samples are listed and are highlighted in the Sequencing Run Details window.
Browse Sequencing Run Details
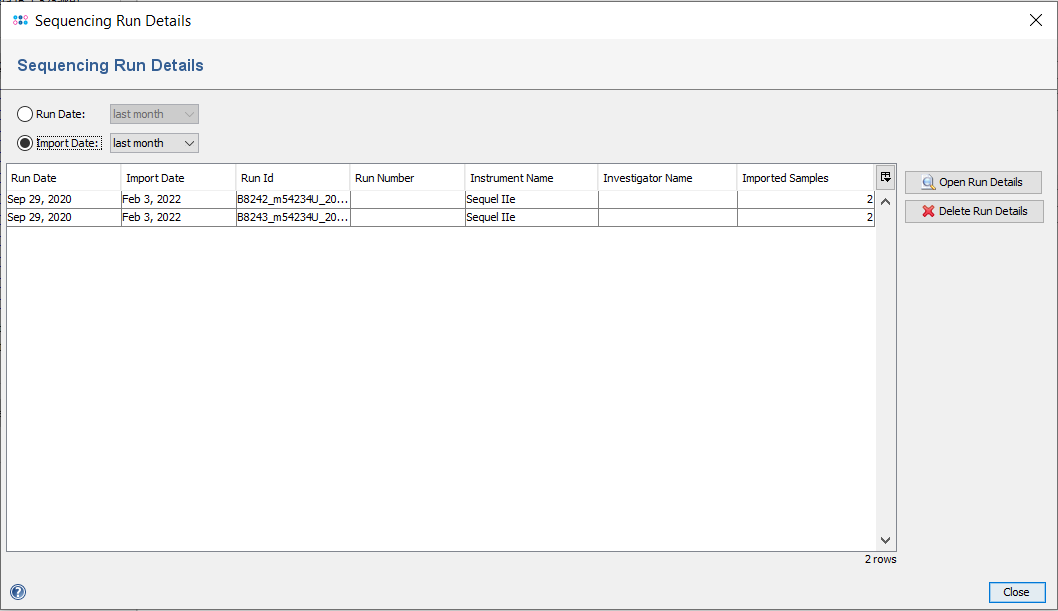
The stored Sequencing Run Details can be accessed in SeqSphere+ using the menu Options | Sequencing Run Details....
The table shows the stored Sequencing Run Details, filtered by one of the two time criteria:
- Run Date: the date when the sequencing run was started, or
- Import Date: the date when the Sequencing Run Details were imported to the SeqSphere+ database.
By double-clicking on a row in the table or by selecting a row and pressing the button Open Run Details, the details of a run can be opened in a new dialog window.
Alternatively, the the run details can also be opened by right-clicking on the field Sequencing Run ID in the procedure tab of a loaded sample.
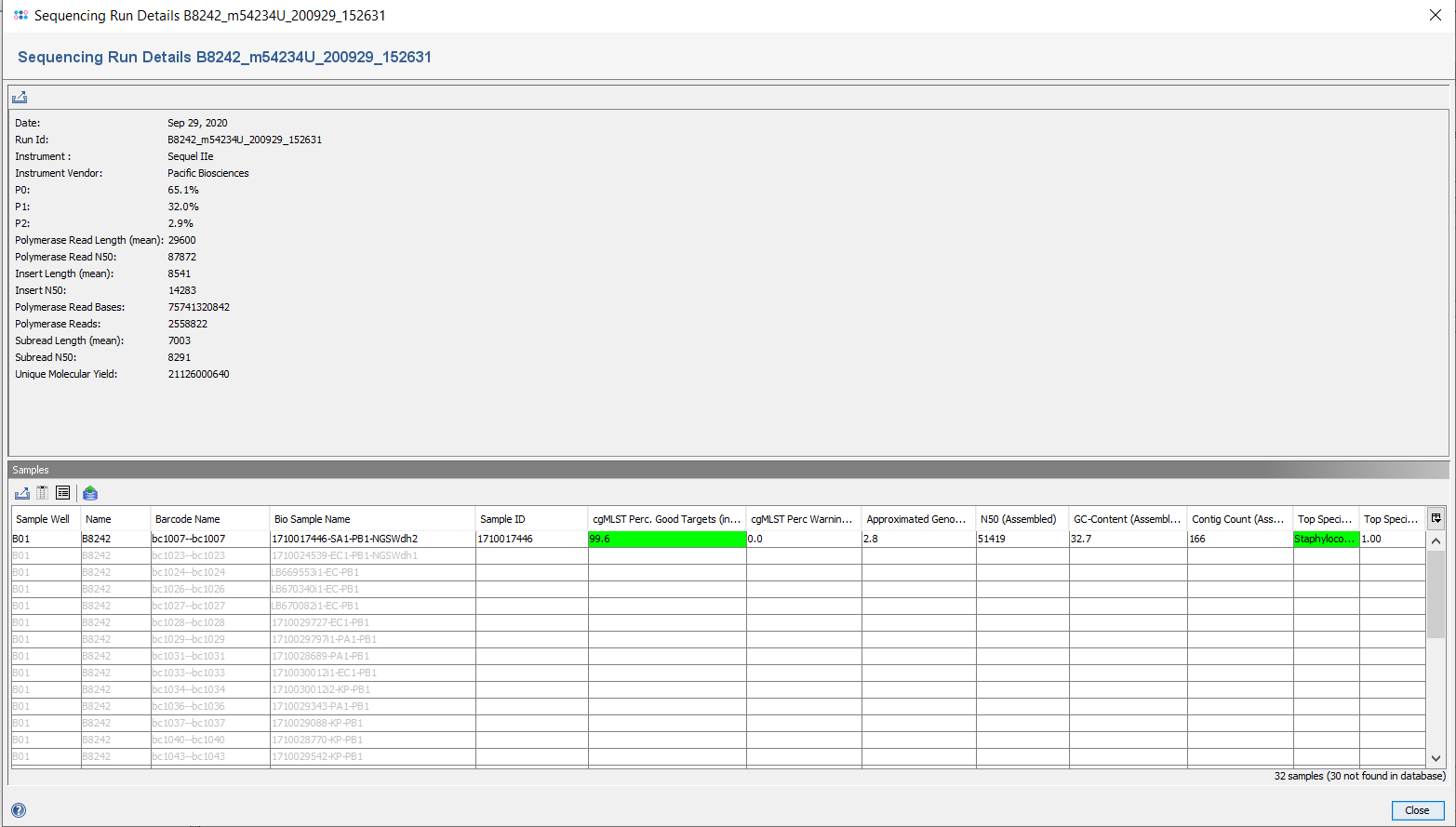
Below the parameters, the sample sheet is listed in a table together with the samples that were already processed. The first four columns are values from the sample sheet, the fifth (Sample ID) and following columns are values from the processed samples. Grayed out rows (that have only the first four columns filled-in) are samples that are defined in the sample sheet, but were not yet processed.
The processed samples can be directly opened from this table by selecting them and using the ![]() load button.
load button.
The parameters, the samples table, and the original sample sheet can be exported.